Empirische Forschung: Warum ich lieber messe als meine
Empirische Forschung in der Softwareentwicklung bedeutet, Annahmen über Methoden, Tools und Teammodelle mit quantitativen Daten von Praktikern zu überprüfen – statt sich auf Konferenz-Hype und Einzelerfahrungen zu verlassen. In meinen Studien mit professionellen Entwicklerinnen und Entwicklern (n=99) zeige ich, wie sich der Unterschied zwischen guter Idee und funktionierender Lösung messbar machen lässt.
Jede Woche erscheint ein neues Framework, ein neues Organisationsmodell, ein neuer Ansatz, der alles besser machen soll. LinkedIn-Posts mit Tausenden Likes erklären, wie Teams sich aufstellen müssen, welche Praktiken überholt sind und warum die Zukunft der Softwareentwicklung ganz anders aussieht als die Gegenwart. Das Problem: Die meisten dieser Aussagen beruhen auf Einzelerfahrungen, Bauchgefühl oder dem, was sich gut anhört.
Meinungen gibt es viele. Daten wenige.
Genau hier setze ich an. Mit quantitativen Studien unter professionellen Entwicklerinnen und Entwicklern überprüfe ich, ob neue Modelle und Methoden in der Praxis tatsächlich funktionieren. Nicht im Labor. Nicht mit Studierenden. Sondern mit Menschen, die jeden Tag Software bauen.
Warum Empirie wichtig ist
Stell dir vor, jemand schlägt ein neues Teammodell für KI-gestützte Entwicklung vor. Klingt überzeugend, die Argumente sind schlüssig, die Konferenzfolien sehen gut aus. Aber stimmen die Annahmen? Teilen Praktikerinnen und Praktiker die Diagnose? Und selbst wenn sie das Modell plausibel finden: Würde es in ihrer Organisation funktionieren?
Genau solche Fragen lassen sich nicht durch Nachdenken allein beantworten. Du brauchst Daten. Du brauchst Menschen, die dir ehrlich sagen, was sie in ihrem Arbeitsalltag erleben. Und du brauchst ein methodisches Instrumentarium, das sicherstellt, dass die Antworten belastbar sind.
Das ist der Kern meiner Forschungsarbeit: den Unterschied zwischen guter Idee und funktionierender Lösung empirisch messbar zu machen.

Zwei Forschungsstränge, ein Prinzip
Meine empirische Arbeit bewegt sich auf zwei Feldern, die unterschiedlicher kaum klingen könnten, aber das gleiche Prinzip teilen: Messen statt Meinen.
UX-Forschung: Der UEQ und UEQ+
Der User Experience Questionnaire (UEQ) und seine Weiterentwicklung UEQ+ sind standardisierte Messinstrumente für User Experience, die ich mitentwickelt habe. Beide werden weltweit eingesetzt, Tausende von Datensätzen aus unterschiedlichsten Produktkontexten bilden inzwischen einen Benchmark, an dem sich neue Produkte messen lassen.
Was den UEQ von vielen anderen Fragebögen unterscheidet: Er wurde von Anfang an psychometrisch validiert. Jedes Item wurde auf Reliabilität geprüft, Faktorenstrukturen wurden analysiert, Benchmarks auf Basis realer Daten aufgebaut. Das klingt trocken, ist aber der Grund, warum die Ergebnisse belastbar sind. Ein Fragebogen, der nicht ordentlich validiert ist, produziert Zahlen, die gut aussehen, aber nichts bedeuten.
Die UEQ-Familie ist auch ein gutes Beispiel dafür, wie aus akademischer Forschung Werkzeuge für die Praxis entstehen. UX-Teams in Unternehmen nutzen den UEQ, um ihre Produkte systematisch zu evaluieren und Verbesserungspotenziale zu identifizieren. Im Kurs Mastering UEQ vermittle ich, wie Teams das Instrument professionell einsetzen. Die Brücke zwischen Wissenschaft und Produktentwicklung ist hier kein frommer Wunsch, sondern tägliche Realität.
KI und Organisation: Wenn Entwicklerteams sich neu aufstellen müssen
Der zweite Strang ist jünger, aber nicht weniger ambitioniert. Zusammen mit Jörg Thomaschewski und Eva-Maria Schön untersuche ich, wie die Integration von KI-Werkzeugen die Organisation von Softwareteams verändert.
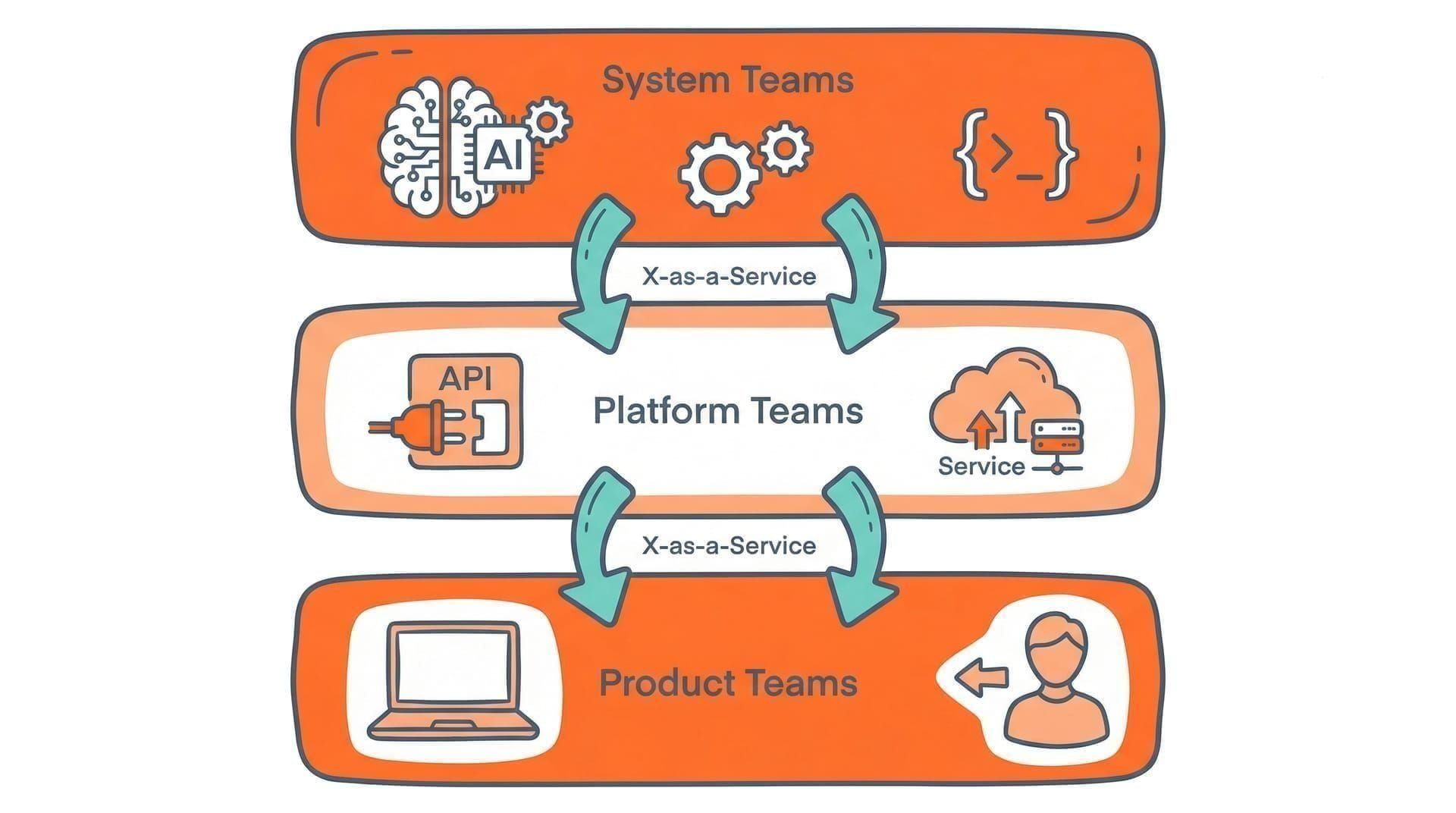
Der Ausgangspunkt war ein Positionspapier, das wir bei der XP 2026 Konferenz vorgestellt haben. Darin argumentieren wir: Die gängige Sichtweise behandelt KI als Werkzeug, das bestehende Teams einfach übernehmen. Wir halten das für zu kurz gedacht. Wenn KI-Werkzeuge zu komplexen, konfigurierten Umgebungen werden, die wir „AI-Dev-Systems" nennen, dann stellt sich nicht mehr nur die Frage, welches Tool ein Team nutzt. Sondern wer diese Systeme baut, wer sie pflegt und wer in ihnen arbeitet.
Unser Vorschlag: ein Drei-Schichten-Modell mit System Teams (die AI-Dev-Systems entwerfen und konstruieren), Platform Teams (die sie nach dem Deployment pflegen und weiterentwickeln) und Product Teams (die innerhalb der kuratierten Umgebung Software entwickeln). Das Modell erweitert bewährte Konzepte aus dem Platform Engineering und den Team Topologies von Skelton und Pais.
Aber ein Positionspapier ist erst der Anfang. Die entscheidende Frage ist: Sehen Praktikerinnen und Praktiker das genauso?
Die Prolific-Studie: 99 Entwickler, 28 Items, ehrliche Antworten
Um die Praxisperspektive systematisch zu erfassen, haben wir eine quantitative Studie mit 99 professionellen Softwareentwicklern durchgeführt, rekrutiert über die Plattform Prolific. Vier Messblöcke mit insgesamt 28 Items auf einer 7-stufigen Likert-Skala (normiert auf -3 bis +3) decken die zentralen Dimensionen ab:
Block C fragt nach wahrgenommenen Veränderungen durch KI-Werkzeuge. Die Ergebnisse sind eindeutig: Entwickler berichten von starken Veränderungen in ihrer Arbeitsweise (M=+1,98) und deutlich schnelleren Iterationszyklen (M=+1,53). Gleichzeitig verschiebt sich die Rolle vom Produzenten zum Steuernden: mehr Produktentscheidungen, weniger reine Implementierung.
Block O untersucht, ob KI-Integration als organisationale Herausforderung wahrgenommen wird. Die zentrale Erkenntnis: Entwickler stimmen stark zu, dass KI-Werkzeuge als geteilte Infrastruktur behandelt werden sollten (M=+1,38), und sie sehen Bedarf an dedizierten Teams für KI-Entwicklungsumgebungen (M=+1,13). Aber sie empfinden die Tool-Fragmentierung noch nicht als akutes Problem (M=+0,46). Die Diagnose wird geteilt, der Leidensdruck fehlt noch.
Block M prüft die Plausibilität des Drei-Schichten-Modells. Hier zeigt sich ein faszinierendes Muster, das wir als Plausibility-to-Applicability Gap beschreiben: Das Modell wird als plausibel bewertet (M=+1,49), aber die Befragten zweifeln, ob es in ihrer eigenen Organisation umsetzbar wäre (M=+0,76). Der Grund? Die meisten Organisationen haben die dafür nötige Reife noch nicht (M=+1,40).
Block A zeigt, dass agile Praktiken sich nicht auflösen, sondern transformieren. TDD wird wichtiger als Spezifikation für KI-generierten Code (M=+1,61), Continuous Integration wird kritischer denn je (M=+1,98). Sprint-Zyklen? Umstritten, aber nicht am Ende (M=+0,33).
Ergebnisse im Überblick
| Messblock | Dimension | Mittelwert (M) | Interpretation |
|---|---|---|---|
| Block C | Veränderung der Arbeitsweise | +1,98 | Starke Zustimmung |
| Block C | Schnellere Iterationszyklen | +1,53 | Deutliche Zustimmung |
| Block O | KI als geteilte Infrastruktur | +1,38 | Starke Zustimmung |
| Block O | Bedarf an dedizierten KI-Teams | +1,13 | Moderate Zustimmung |
| Block O | Tool-Fragmentierung als Problem | +0,46 | Schwache Zustimmung |
| Block M | Plausibilität des Modells | +1,49 | Deutliche Zustimmung |
| Block M | Umsetzbarkeit in eigener Org | +0,76 | Moderate Zustimmung |
| Block A | TDD wird wichtiger | +1,61 | Deutliche Zustimmung |
| Block A | CI wird kritischer | +1,98 | Starke Zustimmung |
| Block A | Sprint-Zyklen relevant | +0,33 | Schwache Zustimmung |
Skala: -3 (starke Ablehnung) bis +3 (starke Zustimmung), n=99 professionelle Softwareentwickler
Was gute empirische Forschung ausmacht
Ich bin überzeugt: Gute Empirie zeichnet sich vor allem durch Transparenz über ihre Grenzen aus — nicht allein durch interessante Ergebnisse.
In unserer Studie haben drei von vier Messblöcken Cronbach's-Alpha-Werte unter dem üblicherweise geforderten Schwellenwert von 0,70. Block O erreicht α=0,571, Block M α=0,585. Manche Reviewer würden hier sofort die Glaubwürdigkeit infrage stellen. Wir machen etwas anderes: Wir erklären, warum das so ist. Diese Blöcke messen bewusst mehrere Facetten eines breiten Konstrukts. Explorative Faktorenanalysen zeigen, dass es innerhalb der Blöcke kohärente Sub-Cluster gibt. Die niedrigen Alpha-Werte spiegeln Multi-Dimensionalität wider, nicht Messfehler.
Das offen zu kommunizieren ist wichtiger als eine perfekte Kennzahl vorzutäuschen. Wer niedrige Reliabilitätswerte versteckt oder wegerklärt, macht keine bessere Forschung. Wer sie transparent diskutiert und durch Sub-Cluster-Analysen absichert, schon.
Dasselbe Prinzip gilt für unbequeme Befunde. Die Plausibility-to-Applicability Gap klingt erst einmal wie eine Schwäche des Modells. Tatsächlich ist sie das informativste Ergebnis der Studie: Praktikerinnen und Praktiker erkennen den Bedarf an organisationaler Veränderung, sehen aber die Umsetzungshürden klar. Das ist keine Absage an das Modell. Es ist der Hinweis darauf, was als Nächstes erforscht werden muss: Implementierungsleitfäden, Reifegrad-Assessments, vereinfachte Varianten für kleinere Teams.
Von Forschungsergebnissen zu konkreten Empfehlungen
Empirische Forschung, die in der Schublade bleibt, ist verschwendete Forschung. Mein Ziel ist es, aus Daten Handlungsempfehlungen abzuleiten, die in der Praxis umsetzbar sind.
Beim UEQ ist das offensichtlich: Ein Benchmark-Vergleich zeigt einem Produktteam sofort, wo ihr Produkt im Vergleich steht und wo die größten Hebel für Verbesserungen liegen. Das ist angewandte Forschung im besten Sinne.
Bei der KI-Organisationsforschung ist der Weg etwas länger. Die Studie zeigt, dass der Bedarf an struktureller Veränderung wahrgenommen wird, aber die Umsetzung eine offene Frage bleibt. Die nächsten Schritte sind deshalb bewusst praxisorientiert: Fallstudien mit Organisationen, die das Modell erproben. Eine vollständige Übersicht aller bisherigen Ergebnisse findest du in meinen Publikationen. Weiterentwicklung des Messinstruments mit besserer Reliabilität für die organisationalen Blöcke. Und die Entwicklung eines Reifegradmodells, das Organisationen hilft einzuschätzen, ob und wie sie das Drei-Schichten-Modell einführen können.
Warum das alles zählt
Du musst kein Forscher sein, um von empirischer Forschung zu profitieren. Aber du profitierst davon, Entscheidungen auf Basis von Daten zu treffen statt auf Basis von Konferenz-Hype. Ob du ein Produktteam leitest, das seine UX verbessern will, oder eine Organisation, die überlegt, wie sie KI-Werkzeuge strategisch einbettet: Irgendwann kommt der Punkt, an dem Meinungen nicht mehr reichen.
An diesem Punkt beginnt meine Arbeit.
Häufige Fragen
Empirische Forschung in der Softwareentwicklung bedeutet, Hypothesen über Methoden, Tools oder Teammodelle mit systematisch erhobenen Daten zu überprüfen. Statt auf Einzelerfahrungen oder Meinungen zu setzen, werden standardisierte Erhebungsinstrumente wie Fragebögen, Interviews oder Experimente eingesetzt, um belastbare Aussagen über die Praxis zu gewinnen.
Eine Stichprobe von 99 professionellen Softwareentwicklern ist für explorative Forschung aussagekräftig, weil sie statistisch stabile Mittelwerte und erste Mustererkennungen ermöglicht. Entscheidend ist vor allem die Qualität der Stichprobe, weniger ihre Größe: Alle Teilnehmer sind berufstätige Entwickler, rekrutiert über die Plattform Prolific mit strengen Qualifikationsfiltern.
Cronbach's Alpha (α) ist ein Maß für die interne Konsistenz eines Fragebogens. Ein Wert ab 0,70 gilt als akzeptabel. Niedrigere Werte bedeuten nicht automatisch schlechte Messung – sie können auf Multi-Dimensionalität hinweisen, also darauf, dass ein Fragenblock bewusst mehrere Facetten eines Themas abdeckt. Transparenz über diese Werte ist ein Qualitätsmerkmal seriöser Forschung.
Der UEQ (User Experience Questionnaire) misst User Experience über sechs feste Dimensionen mit 26 Items. Der UEQ+ ist eine modulare Weiterentwicklung, bei der Teams die relevanten UX-Dimensionen selbst auswählen können. Beide Instrumente sind psychometrisch validiert und haben einen umfangreichen Benchmark zur Einordnung der Ergebnisse.
Die Plausibility-to-Applicability Gap beschreibt das Phänomen, dass Praktikerinnen und Praktiker ein neues Modell zwar als plausibel bewerten, aber gleichzeitig an der Umsetzbarkeit in ihrer eigenen Organisation zweifeln. In unserer Studie bewerteten Entwickler das Drei-Schichten-Modell mit M=+1,49 (plausibel), aber die Anwendbarkeit nur mit M=+0,76. Diese Lücke ist der wichtigste Hinweis für zukünftige Forschung.